整体看来,药物研发的体系,是构建于生物学原理与规律的基础之上。生物学的进步,可以在深度与广度上全面影响药物研发的所有领域。
那么人工智能带来的对蛋白质组学认知的进步,会从哪些方面影响和改变药物研发?
为什么药物会脱靶?为什么药物会有重定向?药物临床试验的结果可以预测吗?药物临床试验为什么会失败?
本文作者郭天南教授将从蛋白质组大数据与人工智能的角度,对于以上问题给出分析和解读。
郭天南教授是西湖大学蛋白质组学大数据实验室负责人,长期从事蛋白质组学相关研究,并将其应用于临床样本的大队列(包括甲状腺癌、前列腺癌等),结合人工智能探索生物标志物,在国际上率先提出将蛋白质组大数据和人工智能相结合的研究策略。
♦ 蛋白质是生命的基础 然而核心奥秘远未解开
从蛋白质的功能说起。
一切生命的表现形式,本质上都是蛋白质功能的体现。如果我们能够了解细胞、组织乃至整个生命体内蛋白质的组成及其活动规律,足够理解不同组织器官在不同生理病理状态下蛋白质组的构成和动态变化,就会对疾病的发生、发展、转归等过程有一个全面的认识,把握疾病诊治的关键,提高药物开发的效率。
事实上,蛋白质研究的巨大价值,早在20年前就被高度关注。在人类基因组计划完成后,有科学家在《Science》杂志兴奋地预言,蛋白质组学将很快取代基因组学成为生命科学研究的焦点。《Nature》杂志的专刊则在显著版面报道了人类蛋白质组学组织(HUPO)的成立,并宣告生命科学正式进入蛋白质组学时代。可以说,蛋白质组学在诞生之初,在科学界光环熠熠,工业界也对之热情洋溢。
然而20年后的今天,与基因组学相比,蛋白质组学的科学研究进展和市场化水平却远远落后。总体来看,蛋白质组学研究目前并未像基因组学那样,在科学研究产生巨大的学术价值,在经济领域形成一个高度规模化的基因产业;相反,其在疾病诊疗和药物开发等领域产生的影响非常有限。蛋白质组学甚至常常被人遗忘。
♦ 传统的蛋白质组学研究的技术和方法不适合复杂的蛋白质系统
有人说,“生”在基因组,“命”在蛋白质组。蛋白质组研究对于生命科学的价值是毋庸置疑的。
那么蛋白质组学发展如此滞后的原因是什么呢?很大程度上是因为蛋白质组学研究面临巨大的技术挑战:传统的蛋白质组学分析技术和方法,并不完全适合用来研究蛋白质系统。
蛋白质系统本身是非常复杂的。人体的一个细胞当中,就包含有数万个蛋白质。这些蛋白质可以运输到不同的地方(如细胞膜、细胞核、线粒体、内质网等),可以相互形成复合物,可以不停地生成和降解,还可以发生翻译后修饰(如磷酸化、乙酰化修饰等)。
与基因组相比,对复杂的、动态的蛋白质系统的研究更为复杂和艰巨。一个人从出生到死亡,绝大多数情况下,基因都是不变的,这也是基因可以用于身份鉴定的原因。但是蛋白质组学则不同,在不同的健康状态下,人体内的蛋白质每时每刻都在发生变化。
那么,对于蛋白质组这样的复杂系统的研究,目前的技术方法是什么样的呢?这就要说到传统的蛋白质组学分析技术和方法的局限性。具体有二:
其一,在研究思路上,传统蛋白质组学是盲人摸象。
现代生命科学与医学研究,很多时候使用Western Blot、ELISA等基于抗体的方法,来测量几个或者是几十个蛋白质(一般不会超过100个)。在测量对象的选择上,研究者一般只选择自己认为重要的、感兴趣的蛋白质。这种研究的主观性极易带来研究方向、结果的片面性。
比如,一个药物进入细胞后,可能会作用于许多蛋白质,但研究者可能仅仅测量细胞内数万个蛋白质当中的几十个,然后分析数据、得出结论、发表论文。而事实上,除了这几十个蛋白质之外,是否还有其他与该药物相关性更强的蛋白质,它们如何相互作用的等等,均无从得知。

Designed by Freepik
其二,在统计方法上,传统的蛋白质组学研究分析方法很难用来理解整个系统。
蛋白质系统的复杂程度远远超出我们的一般认知。当我们通过抗体检测,用Western测量10个蛋白质的时候,仅仅通过条带的粗细,肉眼就可以判断蛋白质的表达丰度。但是如果想动态地监测不同时间范围内的几千甚至上万个蛋白质的变化情况,我们就很难用肉眼去观察并得出有效的实验结果。此外,对这些数以千计的蛋白,也很难为它们都找到一一对应的抗体来进行鉴定。
不能直接用肉眼观察,那应该怎么样去获得有效数据呢?之前研究者使用统计分析的方法,但之后发现这种方法具有极大的局限性。因为传统的统计分析方法只能考虑到研究者已经预设好的影响因素。此外,还有大量的研究者认知范围之外的变量,它们是客观存在的。而对于这些认知范围之外的因素,如果没有很好的定量方法和分析方法去认识,就很难真正清晰地理解整个生物系统。
因此,蛋白质组学的研究,必须找到能够匹配这种复杂系统的分析技术和方法。
♦ 用人工智能+蛋白质组大数据可以突破传统技术和方法的局限性
完整意义上的蛋白质组学,是对细胞或生物体全部蛋白质进行系统鉴定、定量并阐释其生物学功能的一门学科。鉴于蛋白质的复杂性和多变性,这种意义上的蛋白质组学或许很长时间内都是一个科学理想。
而郭天南教授在国际上首次提出“蛋白质组大数据”的概念,就是将蛋白质组大数据和人工智能技术相结合。这一技术或许可以大大加速这一科学理想的实现。
在生命科学和医学研究中,仅仅通过测量DNA和RNA很难获取关于生命活动的最直接信息,很难得知我们即时(此时此刻)的身体健康状态。要想实现这个目的,必须加入蛋白质维度的分析。

Designed by Freepik
以肺癌为例,从基因层面上来看,如果肺癌病人的基因有EGFR突变,那么理论上采用小分子的抑制剂进行靶向治疗可能会有效;如果没有EGFR突变,靶向治疗可能就没有效果。但是实际上,这个关联性却并不总是非常清晰且显而易见。药物在很多患者身上一开始有效,后来逐渐出现耐药性。这时候仅通过基因检测通常难以获得除了这个突变外的更多有效结果。并且肿瘤的基因组突变具有较高的组织异质性,导致活检组织测量的结果有时难以解释。但是如果测量蛋白质组,我们就会发现大量蛋白质的表达失调,造成一些通路的激活或者抑制。
这时候研究人员面临一个新问题,即数据解析的问题:虽然该测量方法准确有效,但是由于涉及的蛋白质种类多、动态范围广,因此蛋白质组数据非常复杂,就需要引入人工智能来进行数据挖掘。

Designed by Freepik
研究复杂的系统需要有大量的观测数据和先进的分析方法。就目前的学科进展而言,大数据科学和人工智能就是一个绝佳的组合方法,在面对此类复杂的问题时发挥出了最大而且有用的功效。缺少其中任何一个方法,我们都很难深入理解动态复杂的蛋白质系统。
引入人工智能的意义可以用交通系统来举例说明。春运、上下班高峰期的交通,很难只凭借若干个交警来协调。此时如果在系统上形成大数据,学习交通线路的规律,就可以发现哪里的道路需要扩张,哪里需要建造高架。这种宏观层面的理解和修改有效且精准。
♦ 人工智能+蛋白质组学给生物医学带来崭新变化
在生物体复杂的生命活动中,目前还存在许多未知或不能理解的问题,这些都有可能通过数据分析蛋白质组的运作来得到解答。
这需要两个步骤:其一是把蛋白质组变成数据的方法,也就是通过质谱测量,将生物样品中的的蛋白质组进行数字化;其二,需要用机器学习或者人工智能的方法去解读数据。
首先需要建立蛋白质信息库,之后将蛋白质的信息对应为一个表型:比如对哪个药物有效,或者是疾病轻症或重症,肿瘤还是非肿瘤等等。在梳理过后,可以发现蛋白质组和表型之间有着一一对应的关系。两者之间的联系,就是计算机的模型,即AI模型。在具体使用时,对新的病人样品进行蛋白质组测量,再与模型结合解析,就可以预测药物是否有效。同时,随着新的数据不断地进入和补充数据库,那么模型就可以得到不断改进。
蛋白质是非常复杂的,必须用大数据的方法,通过采集大数据,才能真正去理解蛋白质的工作原理与对疾病的判断有着怎样的作用。这里以郭天南教授在《Cell》上发表的文章为例。
2020年4月,郭天南实验室在《Cell》在线发表了区分新冠轻重症患者的重要生物标志物研究的文章,这是人工智能和蛋白质组学研究相结合的典型应用。
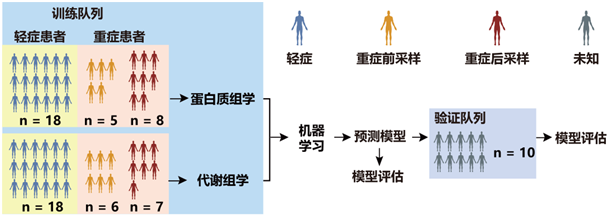
实验设计及流程
团队与临床、代谢组研究团队合作,对99份病毒灭活处理的血清样本进行了安全处理和质谱分析。与对照组、普通流感组和轻症组相比,新冠肺炎重症患者的样本中检测到了93种特有的蛋白表达和204个特征性改变的代谢分子。
在质谱分析数据的基础上,团队使用机器学习方法进一步“沙里淘金”,筛选出重症患者特征性的22个蛋白质和7个代谢物。血清样本成分符合这一组合的患者,很可能是重症患者,或有很大可能性发展为重症病例。
这仅仅是人工智能+蛋白质组学应用于新冠轻重症患者预测的一个案例。试想,如果有足够丰富和高质量的数据,那么将人工智能+蛋白质组学应用于其他类型的临床疾病的病情发展预测,促进医疗资源的合理调配,或许指日可待。
♦ 人工智能+蛋白质组学的突破将改变药物研发
蛋白质是生物功能的主要体现者,它通过自身的一些活动,如修饰加工、转运定位、结构变化,以及蛋白质之间的相互作用等,控制和调控着生命体的许多活动。由于蛋白质组学能够在蛋白质水平上获得关于疾病发生发展、细胞代谢等过程的整体认识,因此也影响着药物研发的方方面面。
特别是人工智能+蛋白质组学的应用,将在药物的靶点确认、药物作用机制等研究方面发挥重要作用,甚至在受试者筛选、药物重定向、药物临床试验结果预测等方面也会有重大价值。
◊ 新靶点的开发
与国内不同,国外制药公司非常重视开发新的药物靶点。目前已经发现的药物靶点约有500个, 而约40%的药物是以G蛋白偶联受体为靶点发现和设计的。
郭天南教授的研究受到制药行业的关注。团队正在同多个国际制药公司合作开发药物靶点。他认为,如果要找新的药物靶点,使用蛋白质组的方法将会非常有效。比如,他们已经通过测量恶性程度增加的大肠癌患者中病理组织的蛋白质组,找到了治疗大肠癌的潜在的新靶点。此外,其研究团队还在探索针对一些医学指征的新的药物靶点,寻找药物疗效的生物标记物。
◊ 药物活性分析
在药物活性测试的环节,如果加入人工智能+蛋白质组学,那么就可以更为准确地评价药物的活性,从药物相关的细胞试验中获得更多的信息。比如MTT试验,一般做法仅仅是检测细胞是否死亡;但如果细胞样品用来做蛋白质组分析,就可以对药物的活性有更深入的理解,甚至可以将这个细胞用几十、几百、或者数以千万计的药物处理后,分析蛋白质组的变化。这样对药物作用的理解就会完全不同。
◊ 受试者筛选
药物临床试验的失败有各种原因,人工智能+蛋白质组学可以应用于受试者筛选。如果能在受试者入组前将其蛋白质组先进行解析,排除既定药物靶点相关通路没有激活的受试者,那么药物临床试验的成功率有可能会大大提高。
◊ 药物临床试验结果预测
人工智能+蛋白质组学还可以用来预测临床试验结果。一般情况下,一个临床试验需要几个月完成,几个月之后才能评价结果的好坏。如果在用药之后,能够定期收集受试者的尿液和血液,针对有效者和无效者的生物样品蛋白质组建立机器学习模型,那就有可能对患者、某种治疗的疗效进行预判,缩短临床试验的时间。
郭天南教授对新冠进行过该方面的研究,通过连续的采样和不同的时间蛋白质组变化的检测以及机器学习建模发现,可以通过前一两个星期的血样,预测某个患者是轻症还是重症。
◊ 药物的联合使用
很多肿瘤,如果只使用一种药物,很容易产生抵抗,通常需要两三个药联合使用,才能达到治疗的效果。但是众多组合如何选择?理论上,可以测定每个药物影响的蛋白质的数据,结合人工智能模型,来分析联合使用会影响什么样的通路,作出判断。
郭天南教授团队已经为各种各样的疾病,如肺癌、肝癌、胃癌等建立了蛋白质数据库。蛋白质数据库是个系统工程,数据库越全面,越能体现蛋白质组大数据的效力。一旦数据库足够大,那么就有可能对生物医药产生巨大且直接的价值。
♦人工智能+蛋白质组学可行性的技术保证
工欲善其事,必先利其器。
人工智能+蛋白质组学的研究得以快速推进,与蛋白质组学分析技术的升级密切相关。主要升级包括三方面:采样技术、样本制备技术和分析速度。
以前蛋白质组学分析的组织样本体积需要黄豆大小,如今采样量可以缩小到1毫克、甚至0.1毫克,都可达到同样的实验目的;以往一次蛋白质组研究能够分析1000~3000个蛋白质,如今通过技术优化,可以一次性分析上万个蛋白质。
此外,一个很重要的进展是,研究团队开发了基于压力循环技术的临床样本的多肽制备方法,可以从1立方毫米(1~2毫克)的临床组织样品中提取50~200微克的多肽,满足上百次质谱分析的用量,从而大大降低了临床病理组织的储存成本。
♦ 将来更需要分子水平的大数据
通常所说的大数据,如病例资料、图像资料、免疫组化、超声、心电图的数据等,主要是文本、影像、声音层面的数据。事实上,在分子层面上更需要大数据。一个细胞中就包含数万个蛋白质,并且所有蛋白质都处于不停地生成和降解当中。对于这样一个复杂的微观的分子世界,目前人类所了解的信息仍然太少。
蛋白质组学研究就可以在这个微观世界中通过测量大量的数据,来理解我们现在不能够理解的跟健康相关的现象、疾病的征兆、最佳治疗药物的选择等等。这有可能完全颠覆社会和大众对健康的理解和对疾病的管控。如果蛋白质组学研究的数据足够丰富,那么人类大健康就进入了另外一个全新的层面和不同的维度。
此外,病理学上更需要分子水平的大数据来协助疾病诊断。
对疾病的理解,以前中医最传统的是望闻问切。后来,西方医学通过解剖实验,发现了各种器官,并且观察出咳嗽的同时肺部存在着问题,再后来发明了显微镜,可以看到光滑的皮肤实际上是由无数个细胞组成,发展了现代病理学。现在的病理诊断主要依赖于细胞水平的形态学检测。
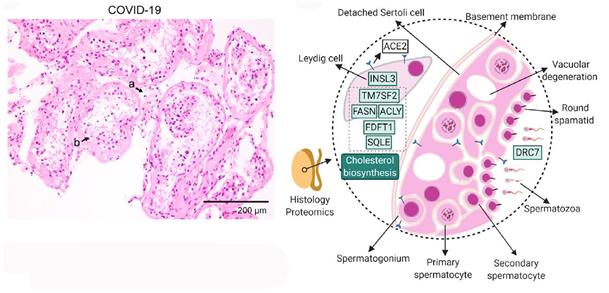
新冠病人的睾丸组织切片以及组织内明显下调的蛋白及相关通路示意图
上左图是因新冠去世的患者的睾丸病理切片,可以看出间质细胞的个数在新冠患者中减少。右图是增加了蛋白质组学研究后,可以看到的分子水平的改变。很多在病理学上看来是相近或一致的病理状态,通过蛋白质组学就可以发现一些重要的差别,准确地说,即在蛋白质水平上会比细胞水平看到得更早、更明显,且“分辨率”更高。
分子水平的大数据同时对药物研发大有帮助。一般来说,很难只通过病理分析来选择治疗药物。但如果能了解了分子水平的改变,就可以找到药物靶点。
总结展望:
蛋白质组学的研究,最近受到的重视程度越来越高。2018年,科技部组织了国际大科学计划,在全国范围内提交申请的500多个项目中,只有3个项目入选为国际大科学计划的第一批项目,其中就包含中国科学院院士贺福初教授领导的人类蛋白质组计划2.0和蛋白质组驱动的精准医学项目。
展望未来,郭天南教授认为,大健康未必只是关乎健康的事情,它同时存在于人工智能的方法应用范围之内。如果可以将大健康与人工智能结合起来,不管从学术角度,从生物学原理的必要性角度,还是从市场、社会的需求来说,都将是时代的大趋势。
作者:郭天南
感谢智药邦侯小龙整理郭天南教授口述信息
原文发表于中国医药报微信公众号、智药邦微信公众号
整体看来,药物研发的体系,是构建于生物学原理与规律的基础之上。生物学的进步,可以在深度与广度上全面影响药物研发的所有领域。
那么人工智能带来的对蛋白质组学认知的进步,会从哪些方面影响和改变药物研发?
为什么药物会脱靶?为什么药物会有重定向?药物临床试验的结果可以预测吗?药物临床试验为什么会失败?
本文作者郭天南教授将从蛋白质组大数据与人工智能的角度,对于以上问题给出分析和解读。
郭天南教授是西湖大学蛋白质组学大数据实验室负责人,长期从事蛋白质组学相关研究,并将其应用于临床样本的大队列(包括甲状腺癌、前列腺癌等),结合人工智能探索生物标志物,在国际上率先提出将蛋白质组大数据和人工智能相结合的研究策略。
♦ 蛋白质是生命的基础 然而核心奥秘远未解开
从蛋白质的功能说起。
一切生命的表现形式,本质上都是蛋白质功能的体现。如果我们能够了解细胞、组织乃至整个生命体内蛋白质的组成及其活动规律,足够理解不同组织器官在不同生理病理状态下蛋白质组的构成和动态变化,就会对疾病的发生、发展、转归等过程有一个全面的认识,把握疾病诊治的关键,提高药物开发的效率。
事实上,蛋白质研究的巨大价值,早在20年前就被高度关注。在人类基因组计划完成后,有科学家在《Science》杂志兴奋地预言,蛋白质组学将很快取代基因组学成为生命科学研究的焦点。《Nature》杂志的专刊则在显著版面报道了人类蛋白质组学组织(HUPO)的成立,并宣告生命科学正式进入蛋白质组学时代。可以说,蛋白质组学在诞生之初,在科学界光环熠熠,工业界也对之热情洋溢。
然而20年后的今天,与基因组学相比,蛋白质组学的科学研究进展和市场化水平却远远落后。总体来看,蛋白质组学研究目前并未像基因组学那样,在科学研究产生巨大的学术价值,在经济领域形成一个高度规模化的基因产业;相反,其在疾病诊疗和药物开发等领域产生的影响非常有限。蛋白质组学甚至常常被人遗忘。
♦ 传统的蛋白质组学研究的技术和方法不适合复杂的蛋白质系统
有人说,“生”在基因组,“命”在蛋白质组。蛋白质组研究对于生命科学的价值是毋庸置疑的。
那么蛋白质组学发展如此滞后的原因是什么呢?很大程度上是因为蛋白质组学研究面临巨大的技术挑战:传统的蛋白质组学分析技术和方法,并不完全适合用来研究蛋白质系统。
蛋白质系统本身是非常复杂的。人体的一个细胞当中,就包含有数万个蛋白质。这些蛋白质可以运输到不同的地方(如细胞膜、细胞核、线粒体、内质网等),可以相互形成复合物,可以不停地生成和降解,还可以发生翻译后修饰(如磷酸化、乙酰化修饰等)。
与基因组相比,对复杂的、动态的蛋白质系统的研究更为复杂和艰巨。一个人从出生到死亡,绝大多数情况下,基因都是不变的,这也是基因可以用于身份鉴定的原因。但是蛋白质组学则不同,在不同的健康状态下,人体内的蛋白质每时每刻都在发生变化。
那么,对于蛋白质组这样的复杂系统的研究,目前的技术方法是什么样的呢?这就要说到传统的蛋白质组学分析技术和方法的局限性。具体有二:
其一,在研究思路上,传统蛋白质组学是盲人摸象。
现代生命科学与医学研究,很多时候使用Western Blot、ELISA等基于抗体的方法,来测量几个或者是几十个蛋白质(一般不会超过100个)。在测量对象的选择上,研究者一般只选择自己认为重要的、感兴趣的蛋白质。这种研究的主观性极易带来研究方向、结果的片面性。
比如,一个药物进入细胞后,可能会作用于许多蛋白质,但研究者可能仅仅测量细胞内数万个蛋白质当中的几十个,然后分析数据、得出结论、发表论文。而事实上,除了这几十个蛋白质之外,是否还有其他与该药物相关性更强的蛋白质,它们如何相互作用的等等,均无从得知。
Designed by Freepik
其二,在统计方法上,传统的蛋白质组学研究分析方法很难用来理解整个系统。
蛋白质系统的复杂程度远远超出我们的一般认知。当我们通过抗体检测,用Western测量10个蛋白质的时候,仅仅通过条带的粗细,肉眼就可以判断蛋白质的表达丰度。但是如果想动态地监测不同时间范围内的几千甚至上万个蛋白质的变化情况,我们就很难用肉眼去观察并得出有效的实验结果。此外,对这些数以千计的蛋白,也很难为它们都找到一一对应的抗体来进行鉴定。
不能直接用肉眼观察,那应该怎么样去获得有效数据呢?之前研究者使用统计分析的方法,但之后发现这种方法具有极大的局限性。因为传统的统计分析方法只能考虑到研究者已经预设好的影响因素。此外,还有大量的研究者认知范围之外的变量,它们是客观存在的。而对于这些认知范围之外的因素,如果没有很好的定量方法和分析方法去认识,就很难真正清晰地理解整个生物系统。
因此,蛋白质组学的研究,必须找到能够匹配这种复杂系统的分析技术和方法。
♦ 用人工智能+蛋白质组大数据可以突破传统技术和方法的局限性
完整意义上的蛋白质组学,是对细胞或生物体全部蛋白质进行系统鉴定、定量并阐释其生物学功能的一门学科。鉴于蛋白质的复杂性和多变性,这种意义上的蛋白质组学或许很长时间内都是一个科学理想。
而郭天南教授在国际上首次提出“蛋白质组大数据”的概念,就是将蛋白质组大数据和人工智能技术相结合。这一技术或许可以大大加速这一科学理想的实现。
在生命科学和医学研究中,仅仅通过测量DNA和RNA很难获取关于生命活动的最直接信息,很难得知我们即时(此时此刻)的身体健康状态。要想实现这个目的,必须加入蛋白质维度的分析。
Designed by Freepik
以肺癌为例,从基因层面上来看,如果肺癌病人的基因有EGFR突变,那么理论上采用小分子的抑制剂进行靶向治疗可能会有效;如果没有EGFR突变,靶向治疗可能就没有效果。但是实际上,这个关联性却并不总是非常清晰且显而易见。药物在很多患者身上一开始有效,后来逐渐出现耐药性。这时候仅通过基因检测通常难以获得除了这个突变外的更多有效结果。并且肿瘤的基因组突变具有较高的组织异质性,导致活检组织测量的结果有时难以解释。但是如果测量蛋白质组,我们就会发现大量蛋白质的表达失调,造成一些通路的激活或者抑制。
这时候研究人员面临一个新问题,即数据解析的问题:虽然该测量方法准确有效,但是由于涉及的蛋白质种类多、动态范围广,因此蛋白质组数据非常复杂,就需要引入人工智能来进行数据挖掘。
Designed by Freepik
研究复杂的系统需要有大量的观测数据和先进的分析方法。就目前的学科进展而言,大数据科学和人工智能就是一个绝佳的组合方法,在面对此类复杂的问题时发挥出了最大而且有用的功效。缺少其中任何一个方法,我们都很难深入理解动态复杂的蛋白质系统。
引入人工智能的意义可以用交通系统来举例说明。春运、上下班高峰期的交通,很难只凭借若干个交警来协调。此时如果在系统上形成大数据,学习交通线路的规律,就可以发现哪里的道路需要扩张,哪里需要建造高架。这种宏观层面的理解和修改有效且精准。
♦ 人工智能+蛋白质组学给生物医学带来崭新变化
在生物体复杂的生命活动中,目前还存在许多未知或不能理解的问题,这些都有可能通过数据分析蛋白质组的运作来得到解答。
这需要两个步骤:其一是把蛋白质组变成数据的方法,也就是通过质谱测量,将生物样品中的的蛋白质组进行数字化;其二,需要用机器学习或者人工智能的方法去解读数据。
首先需要建立蛋白质信息库,之后将蛋白质的信息对应为一个表型:比如对哪个药物有效,或者是疾病轻症或重症,肿瘤还是非肿瘤等等。在梳理过后,可以发现蛋白质组和表型之间有着一一对应的关系。两者之间的联系,就是计算机的模型,即AI模型。在具体使用时,对新的病人样品进行蛋白质组测量,再与模型结合解析,就可以预测药物是否有效。同时,随着新的数据不断地进入和补充数据库,那么模型就可以得到不断改进。
蛋白质是非常复杂的,必须用大数据的方法,通过采集大数据,才能真正去理解蛋白质的工作原理与对疾病的判断有着怎样的作用。这里以郭天南教授在《Cell》上发表的文章为例。
2020年4月,郭天南实验室在《Cell》在线发表了区分新冠轻重症患者的重要生物标志物研究的文章,这是人工智能和蛋白质组学研究相结合的典型应用。
实验设计及流程
团队与临床、代谢组研究团队合作,对99份病毒灭活处理的血清样本进行了安全处理和质谱分析。与对照组、普通流感组和轻症组相比,新冠肺炎重症患者的样本中检测到了93种特有的蛋白表达和204个特征性改变的代谢分子。
在质谱分析数据的基础上,团队使用机器学习方法进一步“沙里淘金”,筛选出重症患者特征性的22个蛋白质和7个代谢物。血清样本成分符合这一组合的患者,很可能是重症患者,或有很大可能性发展为重症病例。
这仅仅是人工智能+蛋白质组学应用于新冠轻重症患者预测的一个案例。试想,如果有足够丰富和高质量的数据,那么将人工智能+蛋白质组学应用于其他类型的临床疾病的病情发展预测,促进医疗资源的合理调配,或许指日可待。
♦ 人工智能+蛋白质组学的突破将改变药物研发
蛋白质是生物功能的主要体现者,它通过自身的一些活动,如修饰加工、转运定位、结构变化,以及蛋白质之间的相互作用等,控制和调控着生命体的许多活动。由于蛋白质组学能够在蛋白质水平上获得关于疾病发生发展、细胞代谢等过程的整体认识,因此也影响着药物研发的方方面面。
特别是人工智能+蛋白质组学的应用,将在药物的靶点确认、药物作用机制等研究方面发挥重要作用,甚至在受试者筛选、药物重定向、药物临床试验结果预测等方面也会有重大价值。
◊ 新靶点的开发
与国内不同,国外制药公司非常重视开发新的药物靶点。目前已经发现的药物靶点约有500个, 而约40%的药物是以G蛋白偶联受体为靶点发现和设计的。
郭天南教授的研究受到制药行业的关注。团队正在同多个国际制药公司合作开发药物靶点。他认为,如果要找新的药物靶点,使用蛋白质组的方法将会非常有效。比如,他们已经通过测量恶性程度增加的大肠癌患者中病理组织的蛋白质组,找到了治疗大肠癌的潜在的新靶点。此外,其研究团队还在探索针对一些医学指征的新的药物靶点,寻找药物疗效的生物标记物。
◊ 药物活性分析
在药物活性测试的环节,如果加入人工智能+蛋白质组学,那么就可以更为准确地评价药物的活性,从药物相关的细胞试验中获得更多的信息。比如MTT试验,一般做法仅仅是检测细胞是否死亡;但如果细胞样品用来做蛋白质组分析,就可以对药物的活性有更深入的理解,甚至可以将这个细胞用几十、几百、或者数以千万计的药物处理后,分析蛋白质组的变化。这样对药物作用的理解就会完全不同。
◊ 受试者筛选
药物临床试验的失败有各种原因,人工智能+蛋白质组学可以应用于受试者筛选。如果能在受试者入组前将其蛋白质组先进行解析,排除既定药物靶点相关通路没有激活的受试者,那么药物临床试验的成功率有可能会大大提高。
◊ 药物临床试验结果预测
人工智能+蛋白质组学还可以用来预测临床试验结果。一般情况下,一个临床试验需要几个月完成,几个月之后才能评价结果的好坏。如果在用药之后,能够定期收集受试者的尿液和血液,针对有效者和无效者的生物样品蛋白质组建立机器学习模型,那就有可能对患者、某种治疗的疗效进行预判,缩短临床试验的时间。
郭天南教授对新冠进行过该方面的研究,通过连续的采样和不同的时间蛋白质组变化的检测以及机器学习建模发现,可以通过前一两个星期的血样,预测某个患者是轻症还是重症。
◊ 药物的联合使用
很多肿瘤,如果只使用一种药物,很容易产生抵抗,通常需要两三个药联合使用,才能达到治疗的效果。但是众多组合如何选择?理论上,可以测定每个药物影响的蛋白质的数据,结合人工智能模型,来分析联合使用会影响什么样的通路,作出判断。
郭天南教授团队已经为各种各样的疾病,如肺癌、肝癌、胃癌等建立了蛋白质数据库。蛋白质数据库是个系统工程,数据库越全面,越能体现蛋白质组大数据的效力。一旦数据库足够大,那么就有可能对生物医药产生巨大且直接的价值。
♦人工智能+蛋白质组学可行性的技术保证
工欲善其事,必先利其器。
人工智能+蛋白质组学的研究得以快速推进,与蛋白质组学分析技术的升级密切相关。主要升级包括三方面:采样技术、样本制备技术和分析速度。
以前蛋白质组学分析的组织样本体积需要黄豆大小,如今采样量可以缩小到1毫克、甚至0.1毫克,都可达到同样的实验目的;以往一次蛋白质组研究能够分析1000~3000个蛋白质,如今通过技术优化,可以一次性分析上万个蛋白质。
此外,一个很重要的进展是,研究团队开发了基于压力循环技术的临床样本的多肽制备方法,可以从1立方毫米(1~2毫克)的临床组织样品中提取50~200微克的多肽,满足上百次质谱分析的用量,从而大大降低了临床病理组织的储存成本。
♦ 将来更需要分子水平的大数据
通常所说的大数据,如病例资料、图像资料、免疫组化、超声、心电图的数据等,主要是文本、影像、声音层面的数据。事实上,在分子层面上更需要大数据。一个细胞中就包含数万个蛋白质,并且所有蛋白质都处于不停地生成和降解当中。对于这样一个复杂的微观的分子世界,目前人类所了解的信息仍然太少。
蛋白质组学研究就可以在这个微观世界中通过测量大量的数据,来理解我们现在不能够理解的跟健康相关的现象、疾病的征兆、最佳治疗药物的选择等等。这有可能完全颠覆社会和大众对健康的理解和对疾病的管控。如果蛋白质组学研究的数据足够丰富,那么人类大健康就进入了另外一个全新的层面和不同的维度。
此外,病理学上更需要分子水平的大数据来协助疾病诊断。
对疾病的理解,以前中医最传统的是望闻问切。后来,西方医学通过解剖实验,发现了各种器官,并且观察出咳嗽的同时肺部存在着问题,再后来发明了显微镜,可以看到光滑的皮肤实际上是由无数个细胞组成,发展了现代病理学。现在的病理诊断主要依赖于细胞水平的形态学检测。
新冠病人的睾丸组织切片以及组织内明显下调的蛋白及相关通路示意图
上左图是因新冠去世的患者的睾丸病理切片,可以看出间质细胞的个数在新冠患者中减少。右图是增加了蛋白质组学研究后,可以看到的分子水平的改变。很多在病理学上看来是相近或一致的病理状态,通过蛋白质组学就可以发现一些重要的差别,准确地说,即在蛋白质水平上会比细胞水平看到得更早、更明显,且“分辨率”更高。
分子水平的大数据同时对药物研发大有帮助。一般来说,很难只通过病理分析来选择治疗药物。但如果能了解了分子水平的改变,就可以找到药物靶点。
总结展望:
蛋白质组学的研究,最近受到的重视程度越来越高。2018年,科技部组织了国际大科学计划,在全国范围内提交申请的500多个项目中,只有3个项目入选为国际大科学计划的第一批项目,其中就包含中国科学院院士贺福初教授领导的人类蛋白质组计划2.0和蛋白质组驱动的精准医学项目。
展望未来,郭天南教授认为,大健康未必只是关乎健康的事情,它同时存在于人工智能的方法应用范围之内。如果可以将大健康与人工智能结合起来,不管从学术角度,从生物学原理的必要性角度,还是从市场、社会的需求来说,都将是时代的大趋势。
作者:郭天南
感谢智药邦侯小龙整理郭天南教授口述信息
原文发表于中国医药报微信公众号、智药邦微信公众号