2023年10月7日,香港科技大学的 Henry Lam 团队在 Nature Communications 上发表了新的文章:Spectroscape enables real-time query and visualization of a spectral archive in proteomics。
文章介绍了一种名为 Spectroscape 的蛋白质组学数据分析平台,它通过实时查询和可视化谱图档案,使用户能够在大规模蛋白质谱数据中实现快速、交互式的谱图聚类和鉴定,有望在蛋白质组学研究中推动数据分析和共享。
蛋白质组学中的串联质谱是蛋白质组学数据的基本单元,现代质谱仪每小时可以轻松产生成千上万个质谱数据。随着这些机器的普及,数据量变得非常庞大。在 ProteomeXchange(蛋白质组学领域的主要数据存储库)中,仅在 2021 年就有超过 5300 个数据集被上传。在这些数据集中,目前在公共领域可用的质谱谱图数量约有数百亿。
传统上,蛋白质组学数据被存储在数据库中,这些库将数据组织成与个别出版物或项目相关的数据集。然而,这种组织方式并不便于数据更好的再利用。因此,一种新的范式是将数据按照谱图相似性进行组织,形成所谓的谱图档案(spectral archive)。
谱图档案保存了所有的谱图,包括已经鉴定和未鉴定的谱图,将相似的谱图聚类在一起。这种组织方式最大限度地提高了数据再利用的潜力。然而,将谱图组织成这种形式的计算成本很高,而且不容易被普通的蛋白质组学研究者所接受。
为了解决这个问题,该论文介绍了一个名为 Spectroscape 的平台,该平台能够实现实时的谱图档案查询和可视化。
该平台利用了 Facebook AI Similarity Search (FAISS) 库中的一种名为 IVF-PQ(Inverted File and Product Quantization)的索引算法,该算法可以在大型谱图档案中实现近似最近邻的快速检索和聚类。
平台允许用户通过谱图相似性搜索整个数据存储库,并在几乎瞬间内获得与查询谱图最匹配的列表以及其邻域中任何聚类的详细结构,从而方便了肽段鉴定的上下文验证和 “暗蛋白质”(dark proteome)的探索。
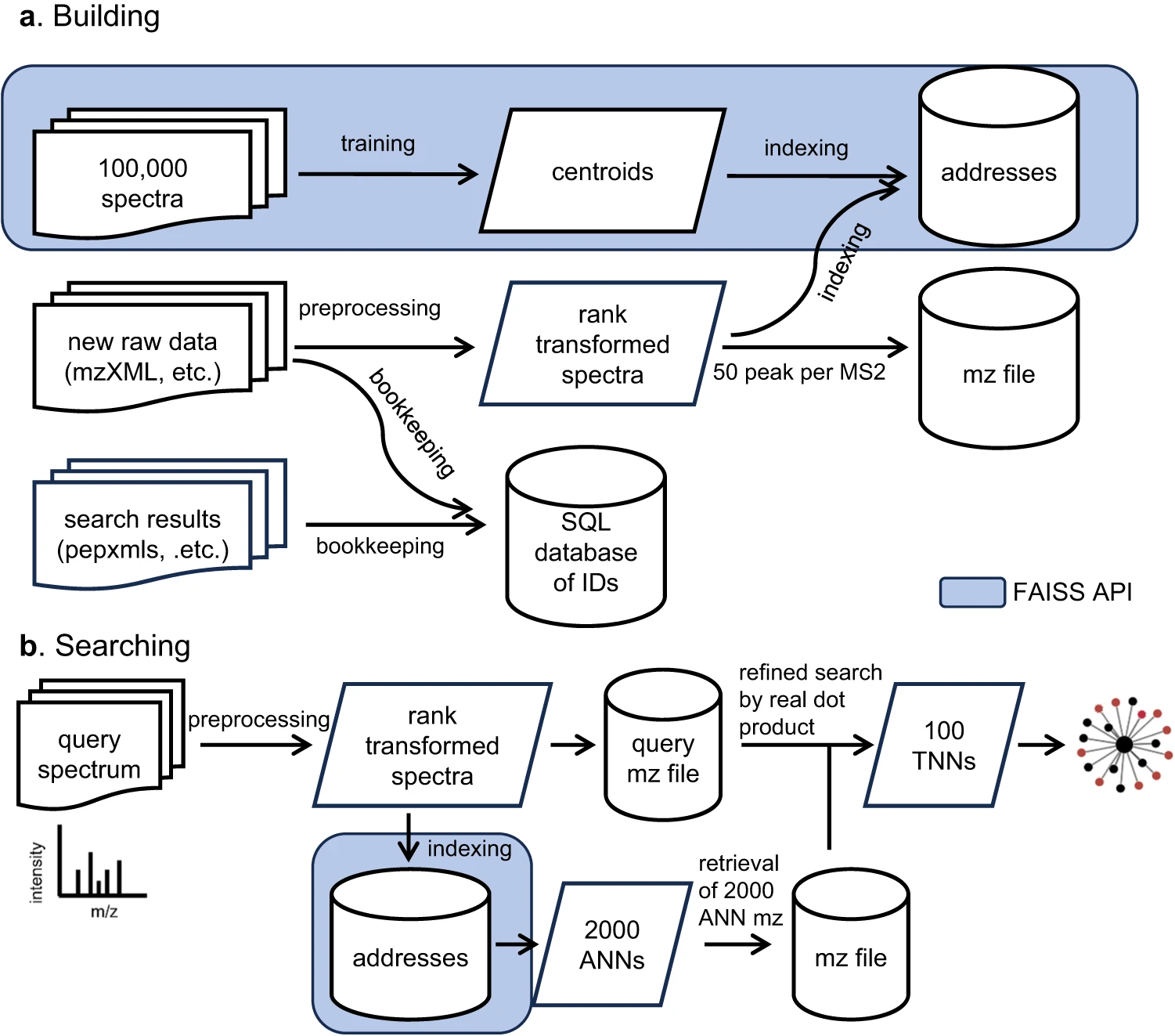
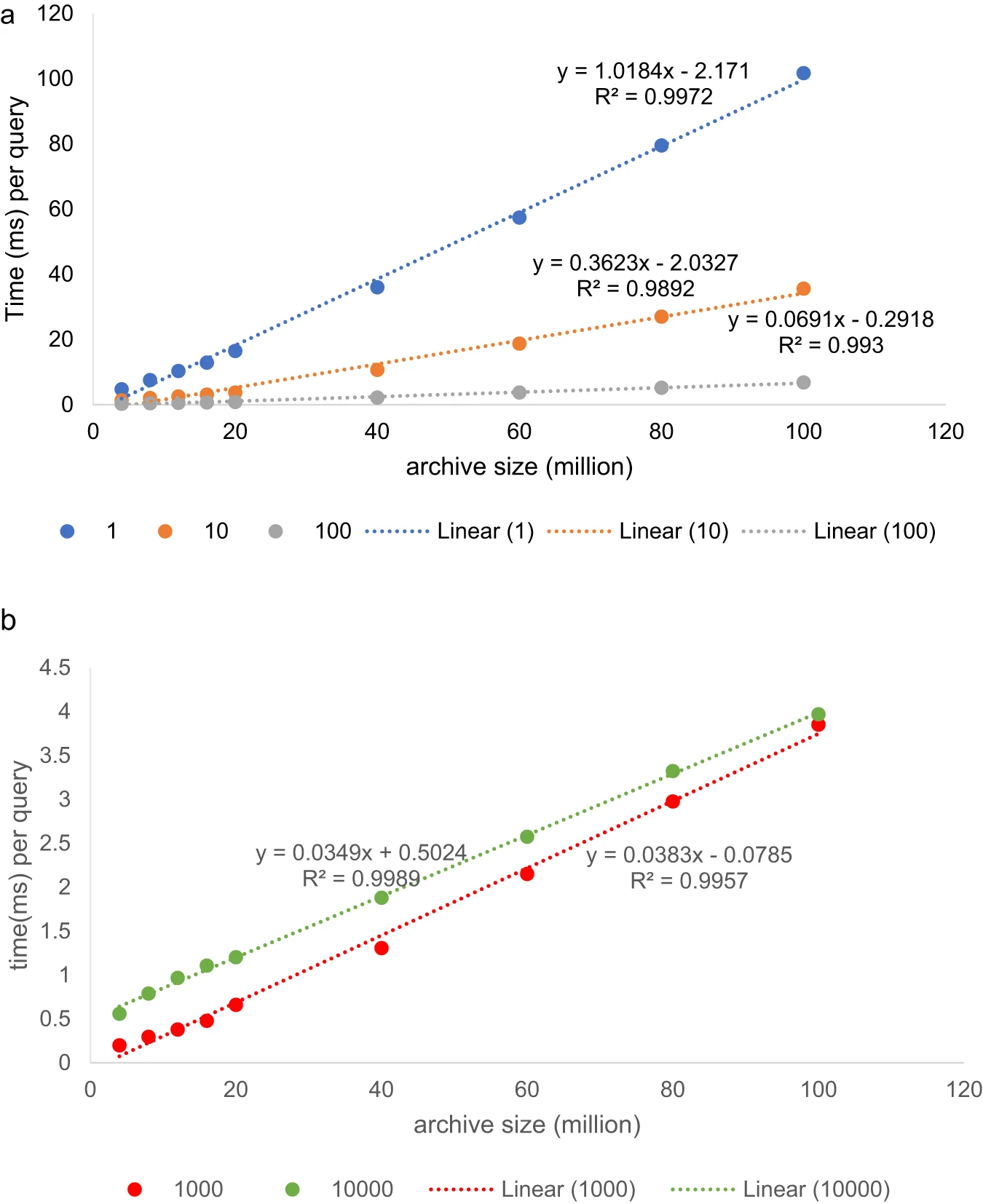
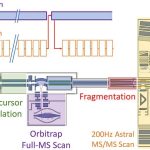
左:通过 Spectroscape 建立和搜索谱图档案 右:ANN 检索的平均时间
Spectroscape的关键特点除了实时查询和可视化、利用 IVF-PQ 算法外,还具有可扩展性和高召回率。Spectroscape 的索引方案允许快速添加新获取的谱图到档案中,而不需要与现有谱图进行比较,从而提高了档案的可扩展性。此外,通过测试,Spectroscape 的总体召回率超过 98%,表明其能够高度准确地找到查询谱图的真实最近邻。
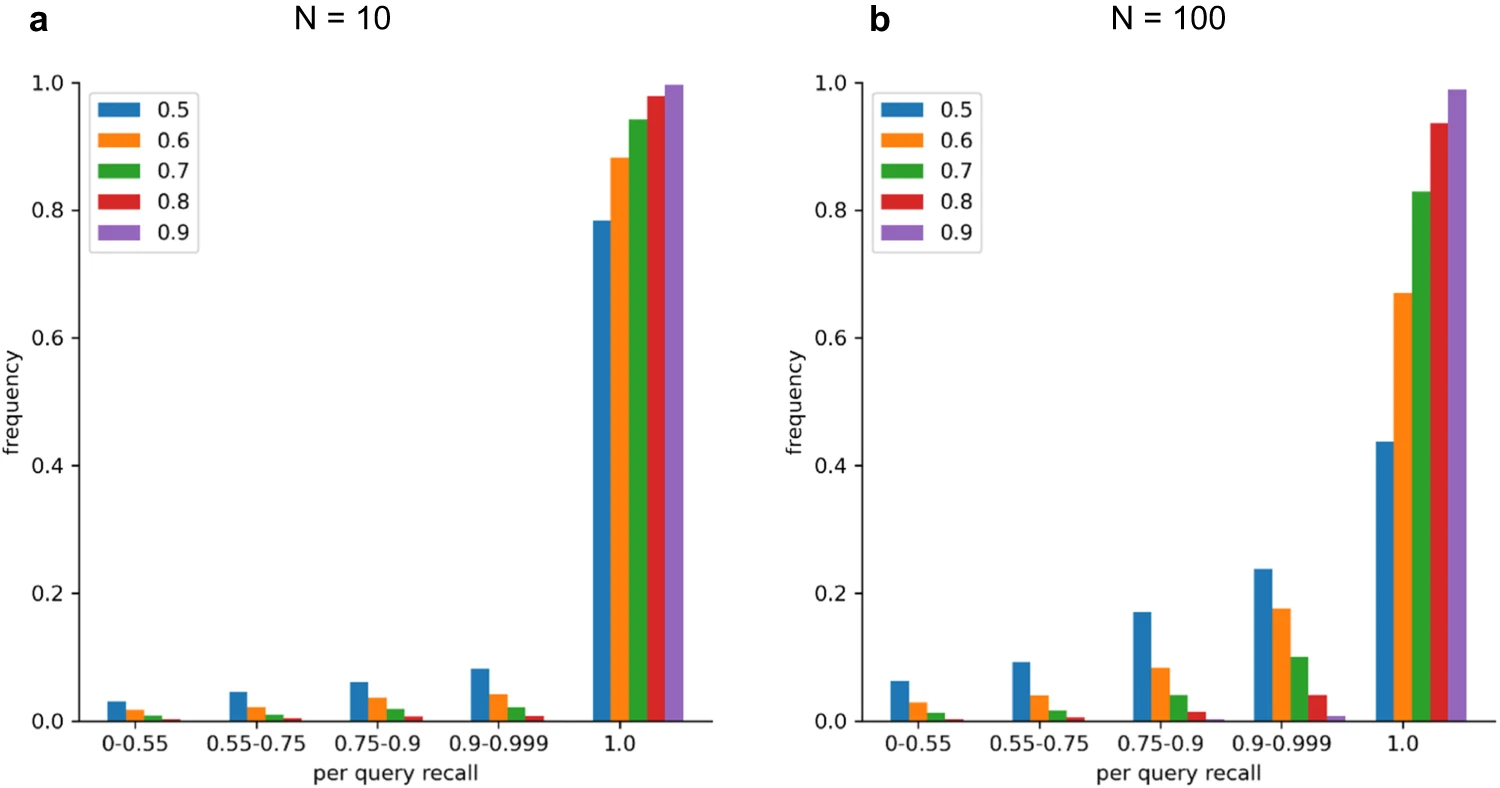
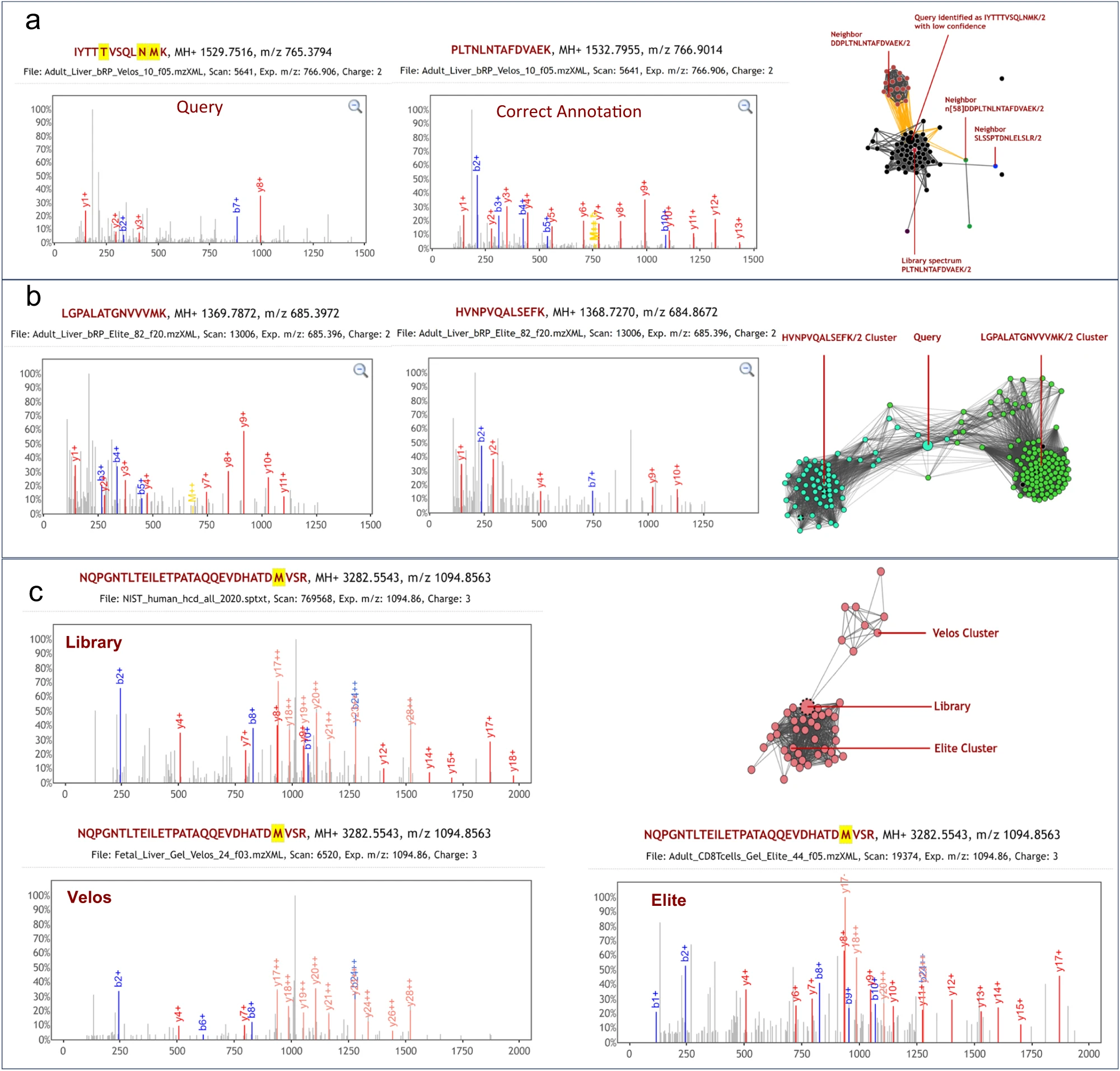
左:通过 Spectroscape 对包含 1.06 亿条谱图的档案进行 TNN 召回 右:Spectroscape 可视化的谱图簇示例
Spectroscape 的网络界面允许用户实时与谱图档案进行交互,并为可视化而设计。作者设想 Spectroscape 最终可以部署为公共存储库中数据分析和数据共享的集成平台,因为查询过程和谱图档案构建过程在算法上是相同的。任何提交的新数据都可以快速建立索引,并成为谱图档案的一部分,并与先前的知识相连。
总的来说,Spectroscape 平台在蛋白质组学中的谱图档案查询和可视化方面具有高效性和准确性,为蛋白质组学研究者提供了一个强大的工具。
论文链接:
https://www.nature.com/articles/s41467-023-42006-x