







11月15日上午,2024大湾区科学论坛大科学计划与国际合作分论坛在广州黄埔国际生物岛举行。
分论坛由广东智慧医学国际研究院和国家蛋白质科学中心(北京)主办,以 “大科学时代下的国际合作与共赢” 为主题,汇聚了美、欧、澳、亚等地区近20个国家的国际顶级专家,国内两院院士,以及企业界、金融界的精英代表共计200余人参加。
上午10点,蛋白质组学和系统生物学领域先驱、苏黎世联邦理工学院教授、人体蛋白质组导航国际大科学计划(π-HuB)理事会主席 Ruedi Aebersold 发表了题为 The π-HuB project: Measuring, understanding and predicting the properties of life 的专题报告。
Ruedi 在报告中指出,π-HuB计划通过整合多组学数据和人工智能以突破当前生命科学研究的局限,实现对细胞行为和生物系统的精准预测,从而推动精准医学和个性化治疗的革命性进展。
我们根据Ruedi的报告全文整理了其主要内容,整理内容未经本人确认,仅供参考,演讲全文请见《人体蛋白质组计划》视频号。

“如果我们想在医学或任何其他生物学领域做出基于机制的预测,我们首先需要理解这些机制是如何运作的。我认为,π-HuB计划是全球最有潜力实现这一目标的倡议,因为它复杂、跨学科且具有国际合作性质。”
Ruedi 的报告主要围绕生命科学中的复杂性与当前研究的局限展开。报告伊始,他介绍了π-HuB计划的目标、背景与进展。他指出,π-HuB计划旨在通过增强对生物学的理解,推动疾病预防、进展和治疗的预测。

π-HuB计划是经过多年规划和多位科学家共同努力的成果。Ruedi介绍到,该计划的规划蓝图目前已被 Nature 期刊接受,共有来自20个不同经济体的101位国际作者参与,这深刻体现了国际合作的精神。他对所有共同作者表示祝贺,并期待π-HuB计划能在中国及相关合作国家政府的支持下实施落地。

生命科学的复杂性与挑战
只有理解了系统的运行方式,才能基于这些理解做出有效预测——这是科学预测的核心原则是。Ruedi 通过简单机械装置(摆钟)的例子来说明了这一点,他指出,“生物学系统远比摆钟复杂”。

细胞内部存在着成千上万的蛋白质分子,它们必须在高度复杂和协调的方式下运作。理解细胞如何维持内稳态、如何应对外部压力以及如何适应新的表型变化是生物学中的两大核心问题。
Ruedi 列举了一些π-HuB计划可能实现的具体目标,例如:判断或预测肿瘤细胞对治疗的耐药性及敏感性、发现新的疾病标志物、为疾病治疗提供新的靶点,以及预测植物如何应对环境压力。他表示,即便大部分研究聚焦于人类生物学,但这些原理和技术同样适用于微生物学和环境生物学等领域。
从数据到模型:
推动生命科学的变革
Ruedi 回顾了20多年前人类基因组计划(Human Genome Project)的成果。虽然我们已经有了大量基因组数据,但仍然无法实现基因组与表型行为之间的准确预测。他列举了几个关键问题,如基因突变如何影响表型、多个突变如何组合产生效应等,这些问题目前尚未得到解决。
同时,尽管我们在数据生成方面取得了显著进展,但在理论方面仍然薄弱。理想的情况是——结合理论和数据,来构建具有预测能力的模型。Ruedi 指出,π-HuB计划的目标之一就是通过大规模的数据集,推动生命科学向能构建预测性模型的方向发展。
医生、律师、公司CEO、政治家等社会角色,在决策时可能会面临艰难的局面,因为他们没有足够的理论和数据支持,只能基于非常有限的证据做出决策。生命科学领域也面临类似问题,但通过π-HuB计划等科学合作,科学家们正努力推动生物学领域从数据积累过渡到能够进行预测的模型。
系统生物学新范式与技术进展
在报告中,Ruedi 从中心法则(genetic central dogma)的 “旧” 概念,谈到系统生物学的 “新” 范式。
根据生命科学的中心法则,遗传信息是从DNA转录成RNA,再翻译成蛋白质,最后到代谢成一些小分子物质。

分子生物学概念和系统生物学概念 图源:《人体蛋白质组计划》视频号直播截图
系统生物学这一新范式强调生物系统是复杂的、可适应的系统,而细胞内的蛋白质及其相互作用正是复杂适应性系统的一个典型例子。Ruedi 指出,将蛋白质的折叠、修饰以及蛋白质之间的相互作用纳入考虑,能够更好地解释细胞如何从基因组信息生成多样化的表型,即 “扩展中心法则”。
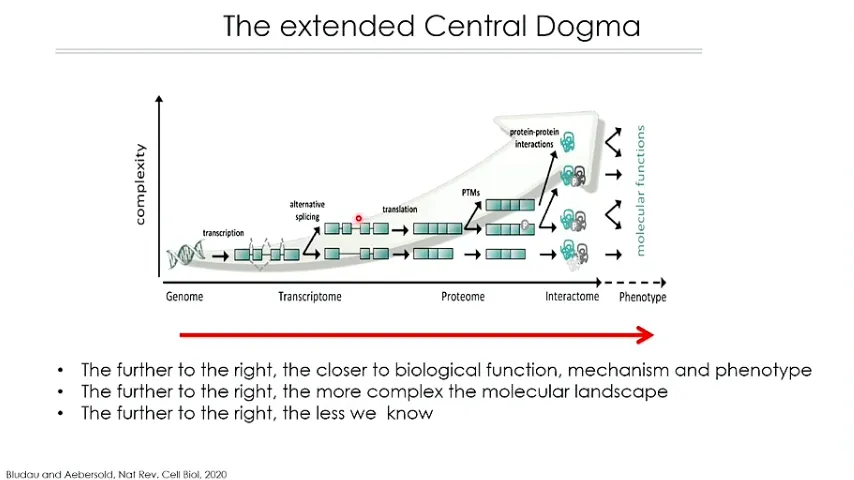
扩展中心法则 图源:《人体蛋白质组计划》视频号直播截图
在这一问题上,π-HuB计划拥有巨大的数据积累潜力,并且能够使用先进的技术,系统地分析生物学系统,填补目前在复杂系统理解上的空白。π-HuB计划的优势在于能够从分子层面向表型层面推进研究,揭示生物学系统的内在规律。
迄今为止,蛋白质组学领域发表的大多数论文都是在这一领域进行的,但转录本和蛋白质的产物是在同一样本中测量的。因此,蛋白质组学领域有大量的文献。这是非常有用的文献。例如,由于医学原因,人们获得了很多关于蛋白质对动态病变的依赖性的见解,但仅凭这些信息还不足以做出真正的基本预测。
Ruedi 分析了现有蛋白质组文献后指出,大多数现有的研究集中在基因到蛋白质的转录翻译,如单一蛋白质组学、单一转录组学等研究,占比约50%;“双” 组学(如蛋白质组学与转录组学结合)研究占比20-30%;而涉及三个或更多层次的多组学研究仍然很少,比例不到10%。

对蛋白质组学现有研究的分析 图源:《人体蛋白质组计划》视频号直播截图
π-HuB计划的独特优势在于能够通过多层次、多组学数据的综合分析,突破现有的局限,将这些数据转化为具有机制性理解的模型。
接着,他介绍了蛋白质组学研究的技术进步与广阔前景。近年来,质谱技术等一系列先进技术的出现,使我们能够在整个 “扩展中心法则” 的过程中系统性地测量从基因到表型的各个层次的变化。例如,化学交联质谱分析使我们能够分析在特定表型背景下蛋白质复合体的动态变化。
而技术的进步,带来的是数据整合的挑战与机会。尽管我们可以产生大量的数据,但如何理解和利用这些数据仍然是一个挑战。π-HuB计划提供了一个独特的机会,通过对细胞或类器官进行 “扰动” 实验(如突变、外部刺激等),收集多个层次的数据,从而形成一个具有高度结构化和信息量的数据集。
同时,他介绍了AI技术的进展在蛋白质组学(尤其是数据分析)中的应用。在π-HuB计划中,利用AI对高度结构化的数据集进行分析,可以实现对生物系统行为的预测。通过这种方法,我们有望像预测钟摆运动那样,对细胞的反应做出准确的预测。Ruedi 表示,π-HuB计划将结合多组学数据和AI技术建立预测模型,进而深化我们对细胞功能的理解。这将不仅为生物学研究带来巨大的进展,还将在医学、生态学等多个领域产生深远影响。
这一过程虽然充满挑战,但随着AI技术的不断进步,生物学领域也有望迎来革命性的突破。
实现π-HuB计划的挑战与全球合作
π-HuB计划的成功将为实现人类基因组计划未曾完成的目标提供新的机遇,弥补我们对生物系统复杂性理解的不足。但同时我们需要认识到:π-HuB计划的实现需要巨大的资金、空间和时间投入。
Ruedi表示,幸运的是,中国中央政府及地方政府、国际合作机构的支持,为项目的实施提供了必要的资源保障。项目的长期性非常关键,不能仅依赖短期的两三年,而是需要一个长期的持续投入和协作。
在π-HuB计划实行期间,如何进行高效、专业的管理和沟通?Ruedi强调,首先要明确各方责任,确保项目的顺利执行和资源的有效分配。其次,需要制定统一的国际合作规则,包括伦理问题、患者同意、样本交换、知识产权等方面的协议。

Ruedi介绍:如何实现π-HuB计划 图源:《人体蛋白质组计划》视频号直播截图
此外,需要建立开放合作的文化,确保不同实验室和国家的科研人员能够共享资源,互相合作,从而推动整个项目的快速进展。同时,要保持创新和应用的持续推进,以应对不断变化的科学挑战。
最后,Ruedi鼓励大家,π-HuB计划需要依赖全球科学家的共同努力和知识共享,只有这样,才能真正释放项目的潜力,并推动生物学、医学等多个领域的突破。
「欧米时刻」
西湖欧米在此次会议特设有展台。
此次会议,我们携 OmniProt™️、FAXP™️、Integral-Omics™️ 等「明星」产品惊艳亮相。

01
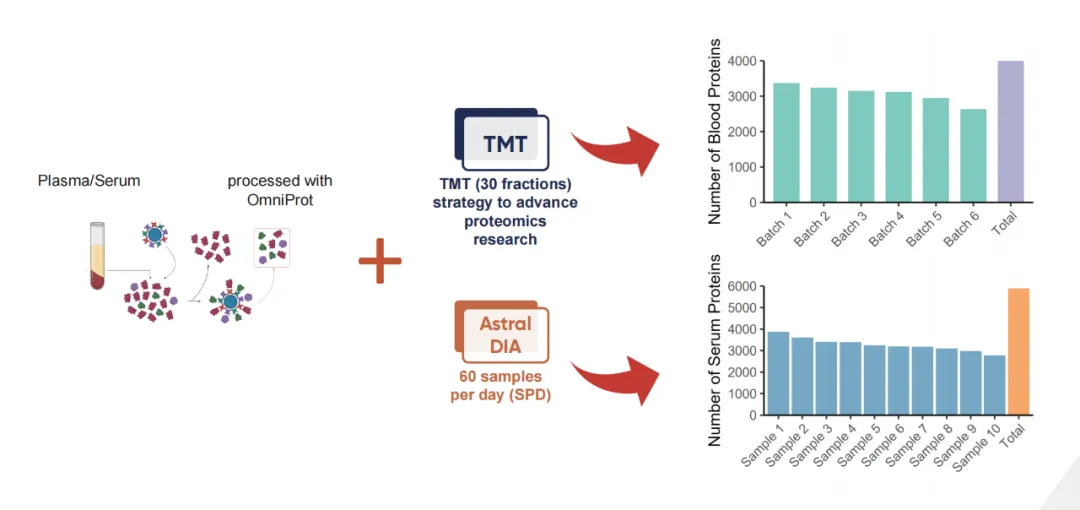
OmniProt™ 高深度血液蛋白质组学平台
OmniProt™️ 高深度血液蛋白质组学服务采用特色化学微粒式富集血液中的中低丰度蛋白,在高灵敏度Astral质谱上使用DIA方法,以达成高深度检测。该平台适用于多种临床应用,尤其在癌症研究中表现出色,提供更为深入的蛋白质组学分析。
02
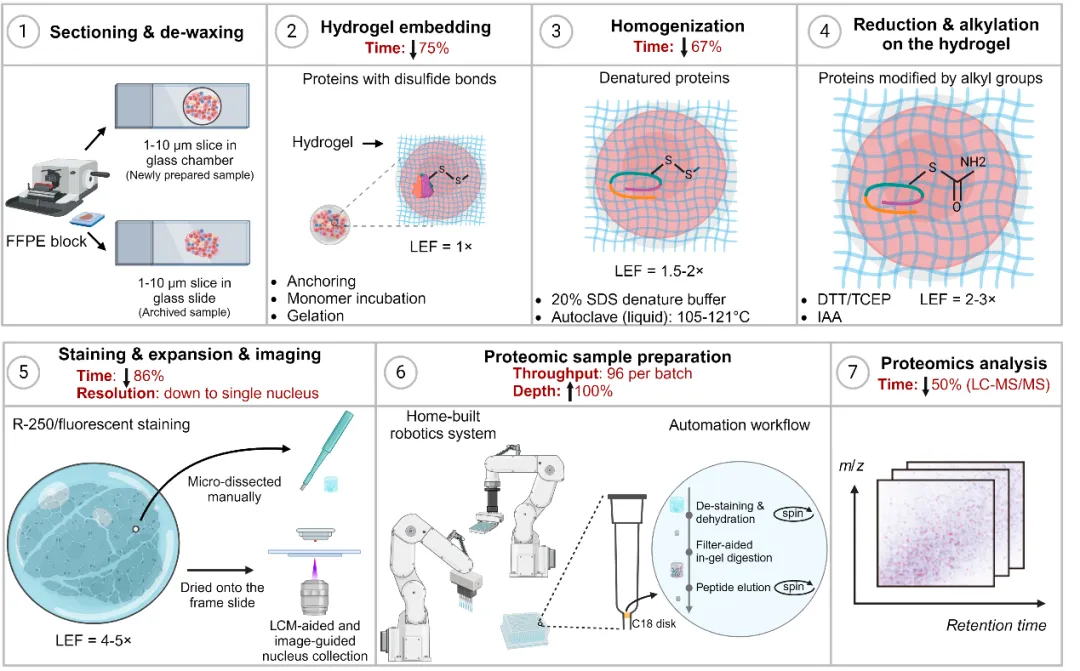
FAXP™️ 组织膨胀蛋白质组学平台
FAXP™️ 是一种新的组织膨胀蛋白质组学分析流程(Filter-aided expansion proteomics, FAXP),结合了基于水凝胶的组织膨胀、滤膜辅助的样本制备流程和基于质谱的蛋白质组学,使得研究者可以在组织水平进行高空间分辨率的蛋白质表达分析。
相比原有的ProteomEx™️(Proteomics+Expansion,可膨胀的蛋白质组技术),FAXP™️ 在部分自动化流程的辅助下表现出14.5倍更高的体积分辨率,增加了肽产量,可鉴定到更多的蛋白质,同时样品制备的时间减少了50%。
03
Integral-Omics™ 多组学整合分析平台
Integral-Omics™ 是一个创新型多组学分析平台,能够从单一样本中连续提取代谢物、脂质、蛋白质、磷酸化肽段、RNA和DNA,并进行全面的多组学分析。Integral-Omics™ 可从低至5-10毫克的新鲜(或冷冻)组织或1×107-2×107个细胞中完成多种组学数据的提取。通过连续提取策略,该平台可大幅提升数据的深度和广度,尤其适用于需要微量样本的研究场景。



