







♦ 基于血浆蛋白质组学发现高级别浆液性卵巢癌预后预测模型
图源:文章图片
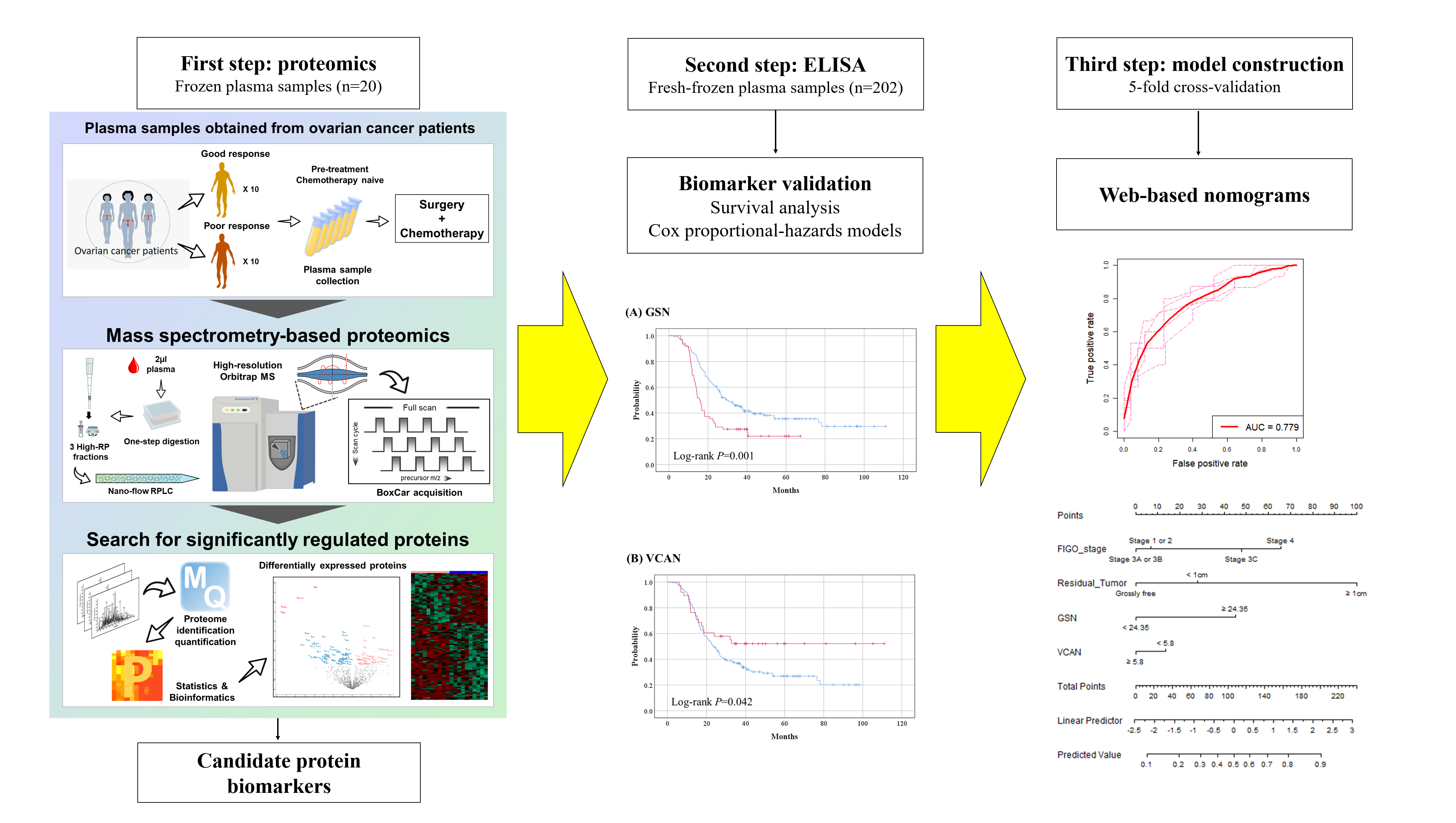
该文首先收集了20例HGSOC病人术前或新辅助化疗前血浆样本,通过无进展生存时间是否大于18个月,将患者分为预后不良和预后良好两组(各10例),通过label-free蛋白质组学鉴定61个蛋白在预后不良组中显著上调。
同时结合该课题组关于卵巢组织中预后相关蛋白的发现(PMID: 32224886),挑选组织和血浆中均在预后不良组中上调的6个蛋白(GSN, VCAN, SND1, SIGLEC14, CD163, PRMT1)在202例验证队列中通过ELISA验证,发现GSN在两组间显著差异表达;同时GSN和VCAN表达量与预后显著相关。
随后,基于5个血浆蛋白生物标志物(SND1因在发现和验证队列中上下调相反而被排除)及临床信息通过回归模型和逐步选择法挑选其中4个特征:FIGO分期,术后残留,血浆GSN和VCAN表达量用于建模,预测患者是否会在术后18个月内复发。最终基于五折交叉验证,得到的模型AUC为0.779。
https://doi.org/10.1016/j.mcpro.2023.100502
♦ 人工智能在药物研发中的应用与技术—回顾AI制药领域的底层逻辑
图源:文章Figure
“AI制药” 虽然是近年来在资本市场逐渐成为了一个相对受人追捧的名词,但这一领域在学术界却已经历了数十年的发展,积累了相对丰富的技术储备。
尽管对于新型的数据形式和药物种类,现有的研究体系和工具可能尚需调整、打磨,但深入理解这一领域的已有逻辑和资源(包括技术目标、公开数据库及相关量化技术、AI模型的类型及功能等)及其相关局限性,是以蛋白质组为代表的组学技术切入AI制药领域的前提基础。
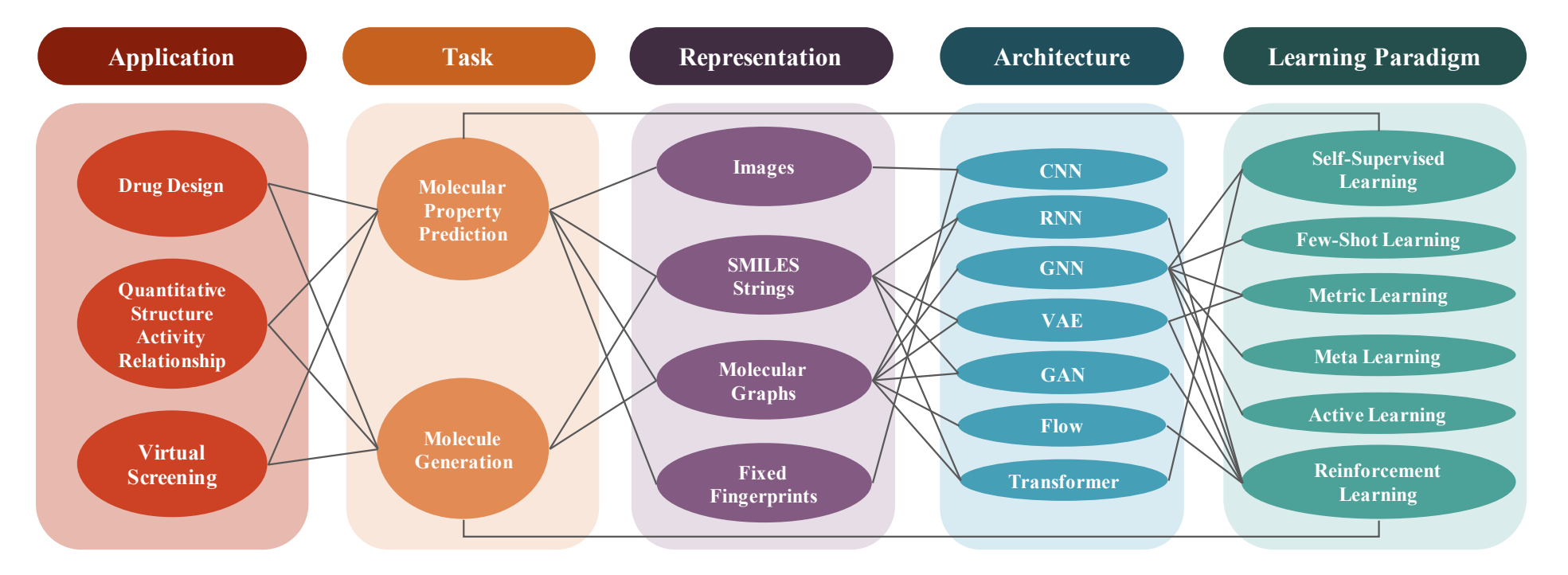
该综述集中介绍了AI在小分子药物研发领域的技术及相关应用,因内容更接近技术的底层逻辑而非简单的进展总结和罗列,具有良好的参考价值。
综述对AI制药领域的技术目标进行了逻辑性的概括,并对近年来的相关综述文献进行了整体的分类;罗列了领域内可用的公开数据集,介绍了化学分子的数字化模式,以及评估计算工具进行分子性质预测及生成能力的可用参考标准;同时,该综述将AI分析技术就模型架构(Model architecture)和学习范式(Learning paradigm)两个方面进行了详细介绍,非常适合领域的初学者以此为指引进行深入拓展学习。
https://doi.org/10.48550/arXiv.2106.05386
评论:张程
♦ 多能干细胞向肝细胞诱导分化过程的蛋白质组动态变化研究

图源:tum.de
图源:文章Abstract
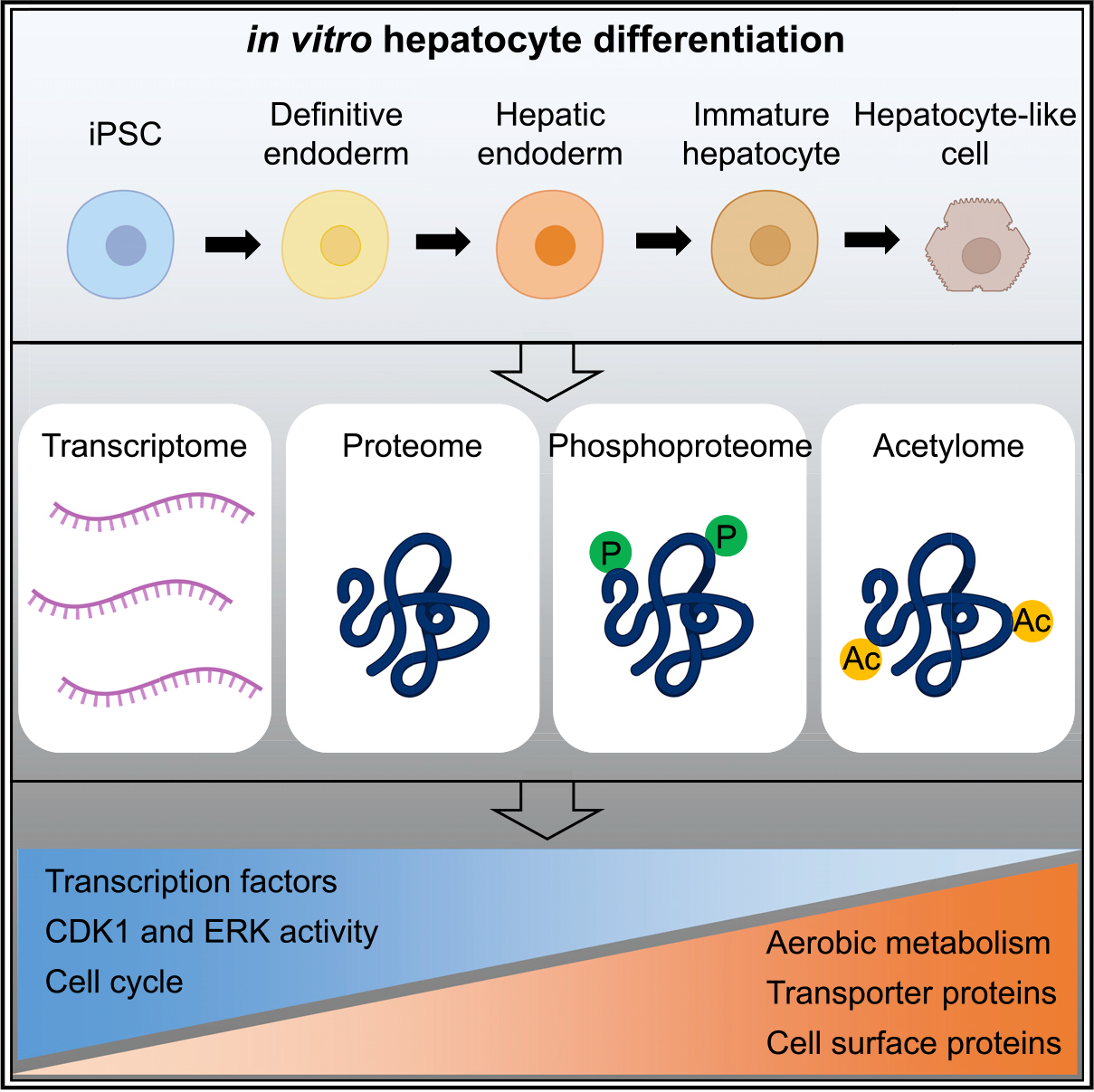
原代人肝细胞被广泛用于评价药物的肝毒性,但原代人肝细胞数量少,培养难度大。干细胞来源的肝细胞被越来越多地讨论为替代品。
为了更好地了解诱导多能干细胞iPSCs向肝细胞分化过程中的时间序列(5个时间点)下的分子变化过程,作者采用标记定量蛋白质组学TMT方法跟踪~9000个蛋白、~12000个磷酸化位点和~800个乙酰化位点的表达。分析揭示了特定阶段的标记物,即肝内胚层与未成熟肝细胞样细胞之间的主要分子变换,例如,代谢、细胞周期、激酶活性和药物转运蛋白的表达。
将二维(2D)和三维(3D)来源的肝细胞与胎儿和成人肝脏的蛋白质组进行比较,表明体外模型的胎儿状态和重要ADME/Tox蛋白的低表达,并不能用于表征药物代谢动力学和毒理学的相关参数。
以上数据使构建肝细胞发育的分子路线图成为未来研究的宝贵资源。
评论:这篇文章作为一个资源性论文,从时间分辨率的多重蛋白质及其修饰组学的层面上进行剖析,其中联合了单细胞和转录组的数据分析,揭示了每个阶段的特点,和阶段与阶段之间切换时的多层次蛋白质组学的变化,进一步对2D和3D培养进行比较,最后落脚到药物的相关参数评价的具体实践指导价值的评估。
https://doi.org/10.1016/j.celrep.2022.110604
评论:孙耀庭
♦ inSPIRE:一个使用Prosit谱预测提高质谱识别率的开源工具
图源:文章Abstract
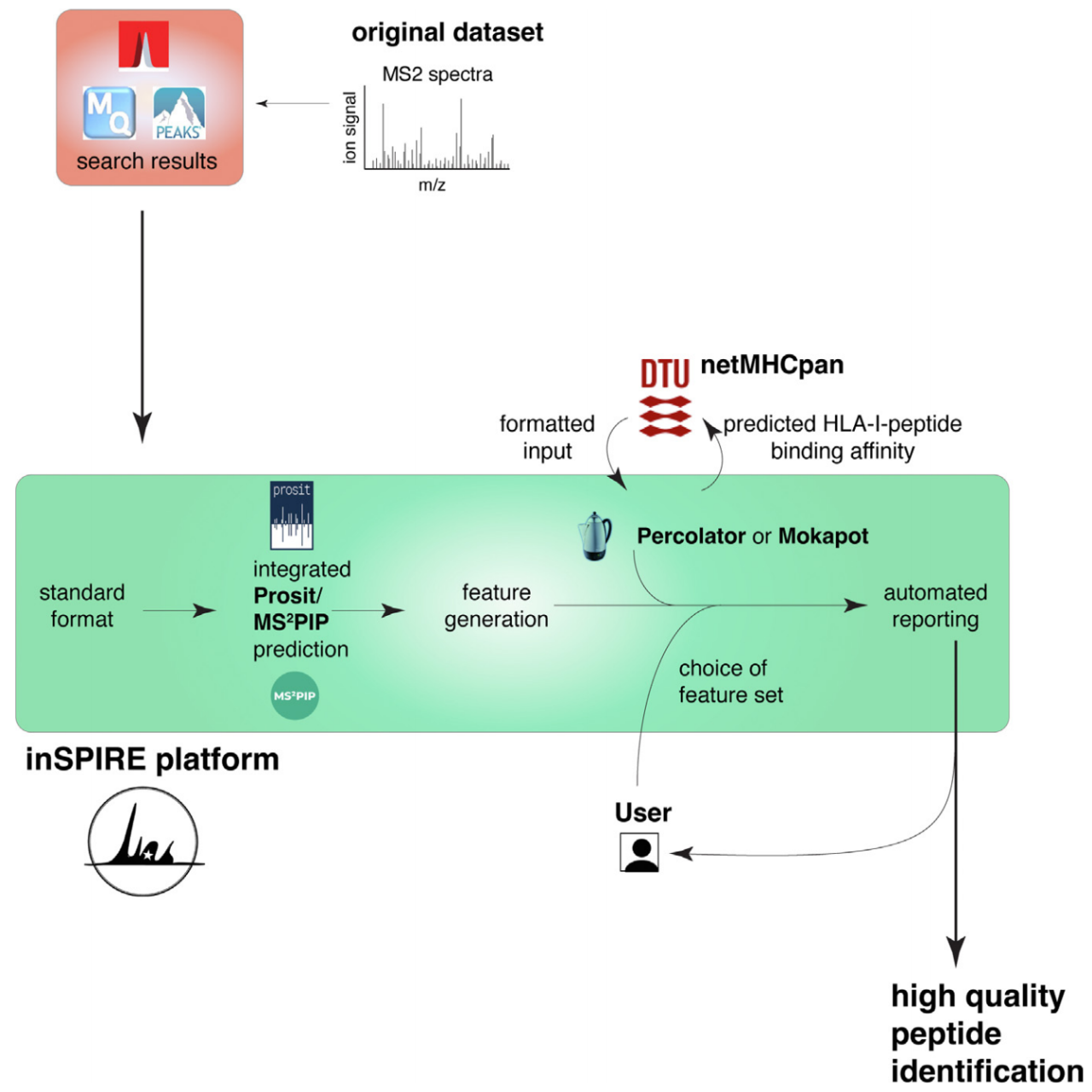
这篇文章开发了一个基于Prosit(Bernhard Kuster & Mathias Wilhelm在19年发表的基于深度学习的肽串联质谱proteome-wide预测DOI: 10.1038/s41592-019-0426-7)谱预测的开源工具(inSPIRE),从Mascot、PEAKS或MaxQuant等软件的搜索结果文件或中间文件中获取输入,并与Prosit进行交互,提高了质谱的识别率。
与Prosit相比,inSPIRE具有更高的灵活性和高效性,它能跟多种数据库兼容,并且允许多个文件的数据进行大规模的rescoring。
作者使用一组HLA-I immunopeptidome数据集,通过PSM鉴定比较,多肽识别精度(number of correctly identified peptides over number of identified peptides)和召回率(number of correctly identified peptides over number of correct peptides)等方面表明inSPIRE相比较Prosit具有一定的优势,在相同99%精度下,inSPIRE比Prosit的召回率最高提高了3%。
https://doi.org/10.1016/j.mcpro.2022.100432
评论:薛张芝


